
大快大数据开发框架的构成模块
大数据也不是近几年才出现的新东西,只是最近几年才真正意义上变得热门、火爆!而这要得益于互联网信息技术的快速发展,网络改变世界、改变生活,大数据技术的应用让这样的改变更为深刻。
关注大数据或者是互联网方面新闻的人应该知道,大数据已经上升到了国家战略的高度。可以说这是时代发展的必然趋势,从国家战略层面推进大数据技术的普及与应用,一个至关重要且非常核心的问题——数据安全问题就非常突出。解决数据安全问题,必然要回归到大数据开发所使用的框架!

国内的大数据开发起步较晚于国外,所有关于大数据大开发的各种标准和规则都是采用国外的那一套。国内做大数据开发的企业或者机构组织所推出的大部分商业发行版本都是对开源程序的二次包装,从事大数据底层开发的少之又少。做大数据原生态开发且又推出商业发行版的,行业也就只有大快搜索,可能在未来的三五年内也许还会有做大数据原生态开发的出现。
为何大数据的普及度不高,主要是由于大数据的应用开发太过偏向于底层,学习的难度不是一般的大,所涉及到的技术面广太大,不是一般人所能够驾驭得了的。市场上大部分打着hadoop国产发行版,也只是把国外的拿过来重新修改了一下而已。大快DKhadoop把大数据开发中的一些通用的,重复使用的基础代码、算法封装为类库,在很大程度上降低了开发的难度。相信这个对于从事开发的人员看了就更容易懂了。
下面,就给大家介绍看一下大快的大数据开发框架的模块构成都有哪些:
大快大数据一体化开发框架主要由六部分组成:数据源与SQL引擎、数据采集(自定义爬虫)模块、数据处理模块、机器学习算法、自然语言处理模块、搜索引擎模块。
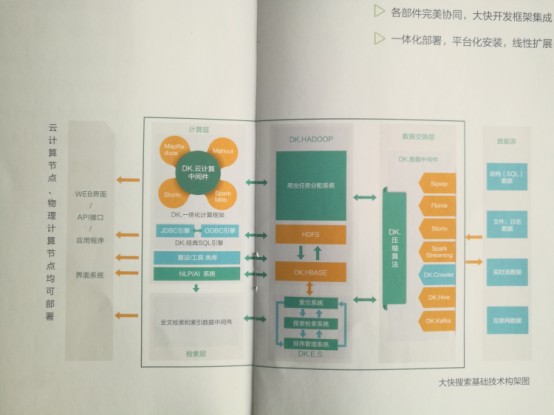
如果在开源大数据框架上部署大快的开发框架,需要平台的组件支持如下:
数据源与SQL引擎:DK.Hadoop、spark、hive、sqoop、flume、kafka
数据采集:DK.hadoop
数据处理模块:DK.Hadoop、spark、storm、hive
机器学习和AI:DK.Hadoop、spark
NLP模块:上传服务器端JAR包,直接支持
搜索引擎模块:不独立发布